04. CNN & Sliding Windows
A Convolutional Approach to Sliding Windows
Let’s assume we have a 16 x 16 x 3 image, like the one shown below. This means the image has a size of 16 by 16 pixels and has 3 channels, corresponding to RGB.

Let’s now select a window size of 10 x 10 pixels as shown below:

If we use a stride of 2 pixels, it will take 16 windows to cover the entire image, as we can see below.

In the original Sliding Windows approach, each of these 16 windows will have to be passed individually through a CNN. Let’s assume that CNN has the following architecture:
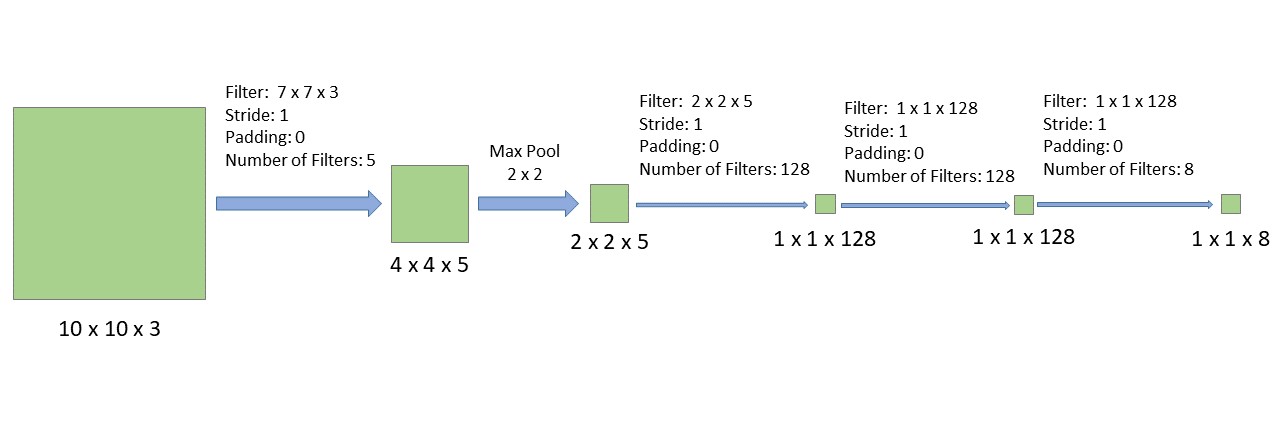
The CNN takes as input a 10 x 10 x 3 image, then it applies 5, 7 x 7 x 3 filters, then it uses a 2 x 2 Max pooling layer, then is has 128, 2 x 2 x 5 filters, then is has 128, 1 x 1 x 128 filters, and finally it has 8, 1 x 1 x 128 filters that represents a softmax output.
What will happen if we change the input of the above CNN from 10 x 10 x 3, to 16 x 16 x 3? The result is shown below:
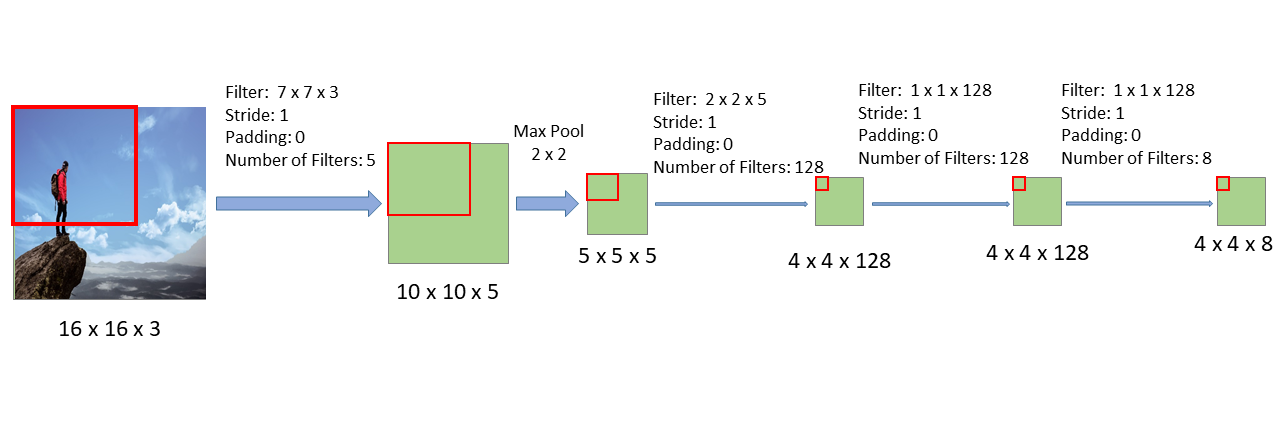
As we can see, this CNN architecture is the same as the one shown before except that it takes as input a 16 x 16 x 3 image. The sizes of each layer change because the input image is larger, but the same filters as before have been applied.
If we follow the region of the image that corresponds to the first window through this new CNN, we see that the result is the upper-left corner of the last layer (see image above). Similarly, if we follow the section of the image that corresponds to the second window through this new CNN, we see the corresponding result in the last layer:
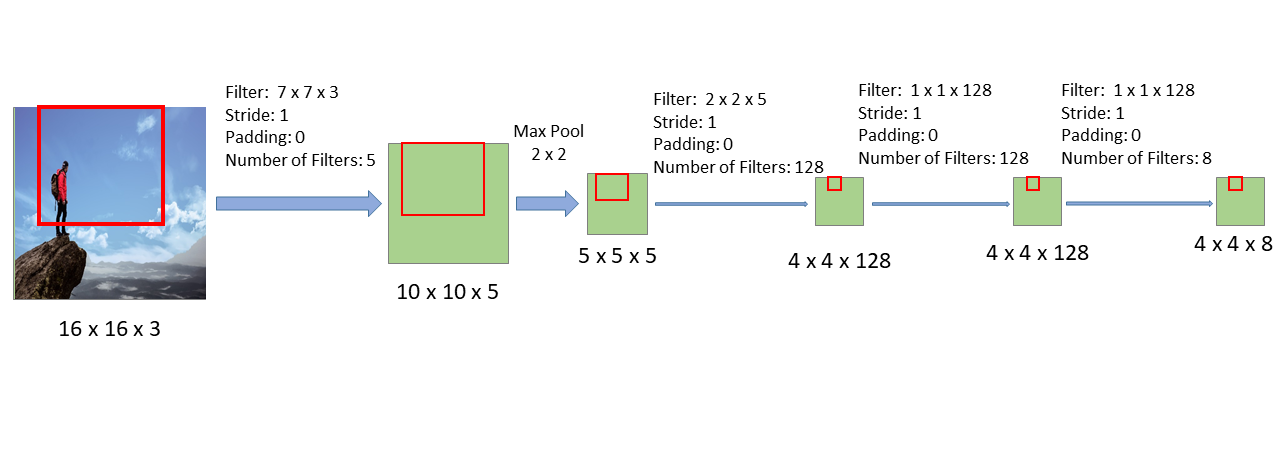
Likewise, if we follow the section of the image that corresponds to the third window through this new CNN, we see the corresponding result in the last layer, as shown in the image below:
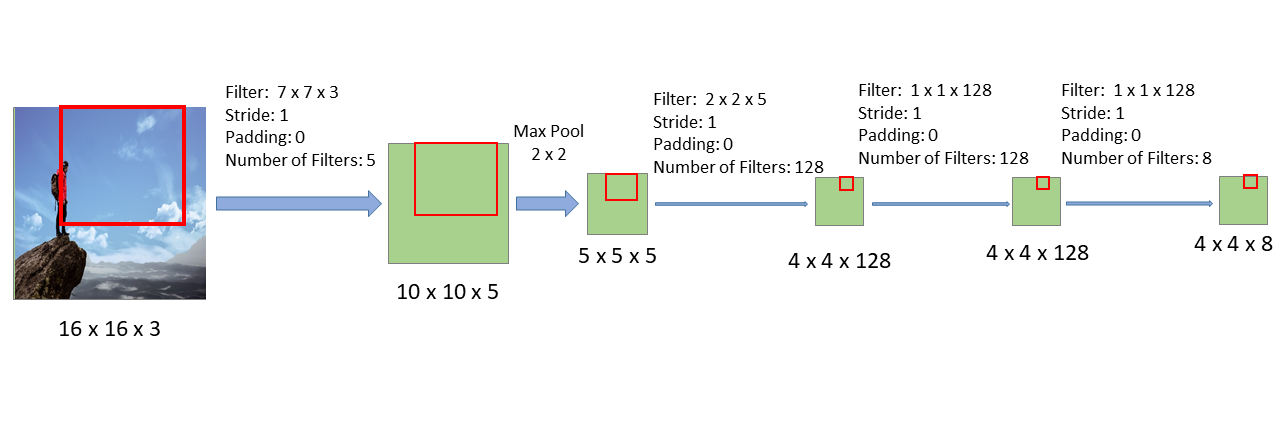
Finally, if we follow the section of the image that corresponds to the fourth window through this new CNN, we see the corresponding result in the last layer, as shown in the image below:
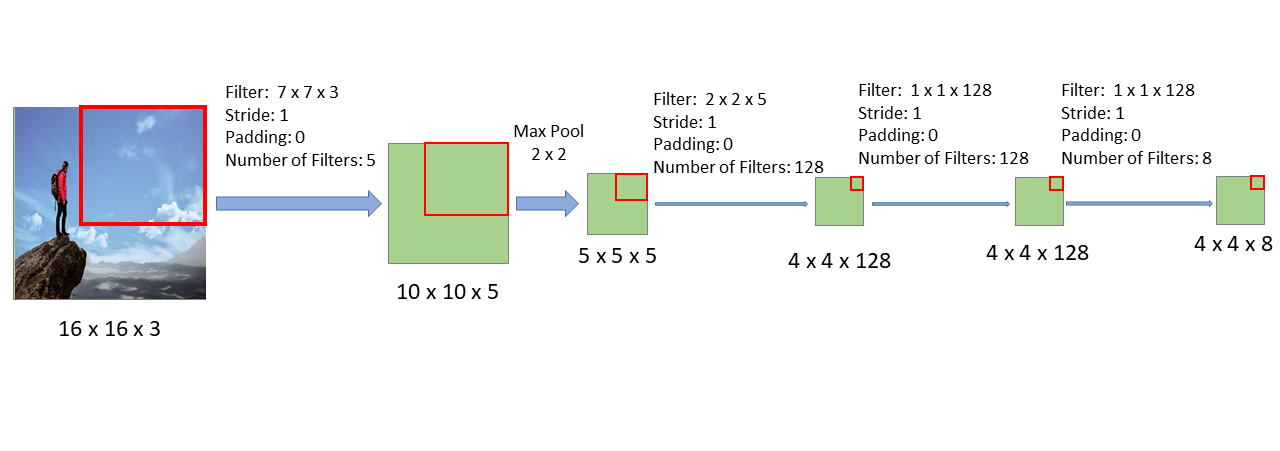
In fact, if we follow all the windows through the CNN we see that all the 16 windows are contained within the last layer of this new CNN. Therefore, passing the 16 windows individually through the old CNN is exactly the same as passing the whole image only once through this new CNN.
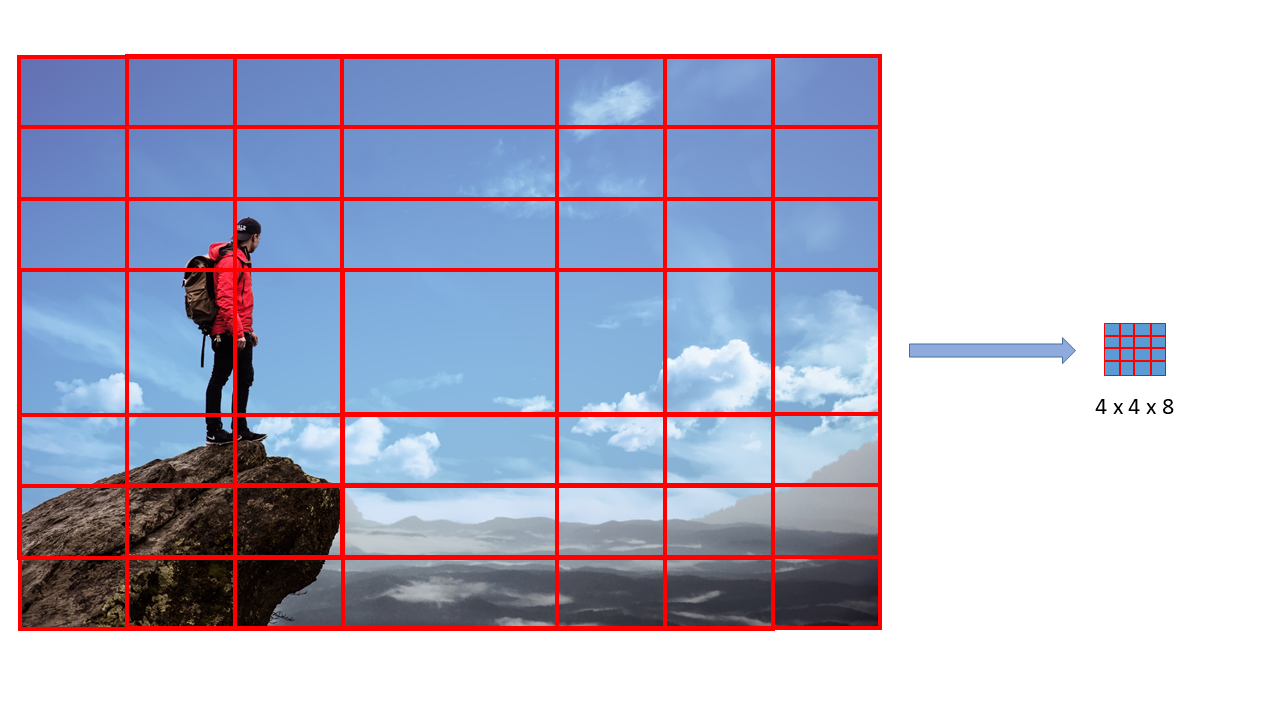
This is how you can apply sliding windows with a CNN. This technique makes the whole process much more efficient. However, this technique has a downside: the position of the bounding boxes is not going to be very accurate. The reason is that it is quite unlikely that a given size window and stride will be able to match the objects in the images perfectly. In order to increase the accuracy of the bounding boxes, YOLO uses a grid instead of sliding windows, in addition to two other techniques, known as Intersection Over Union and Non-Maximal Suppression.
The combination of the above techniques is part of the reason the YOLO algorithm works so well. Before diving into how YOLO puts all these techniques together, we will look first at each technique individually.